普通莫队算法
概览
莫队其实是分块的变化版,没有完全分块。
但莫队的题目一般比分块的题目比较好看一些,其中的“好看”指的是很好看出这是个莫队/分块的题。
接下来说一下莫队能解决的题型。
解决题型
莫队一般解决以下问题:
给你一些信息,和 $q$ 次询问,每次询问可以抽象为一个区间。
而且这个问题还要满足一些条件:
- 可以离线
- 不能有修改(当然带修莫队支持修改,不过普通莫队就不行了)
- 从 $[l,r]$ 的答案可以很快转移到 $[l-1,r]$、$[l+1,r]$、$[l,r-1]$、$[l,r+1]$ 的答案
解决方法
这种题型有个解决方法。
还是先从暴力说起。
暴力做法
看见这个问题的最后一个条件没?这个条件就启发我们从第一个问题的答案,暴力调整左、右端点,去得到第二个问题的答案,以此类推。
这种暴力做法的复杂度一般为 $O($ 任意相邻两个问题的左、右端点差之和 $)$。
而这个算法可以用一种数据卡掉:
- 左、右端点的值的最大值 $n$ 调到最大,把询问次数 $q$ 也调到最大。
- 然后的 $q$ 次询问里,交替询问 $1 \sim n$ 和 $n \sim n$。
于是,复杂度被卡到 $O(qn)$。
一次优化
这个做法的复杂度是无法接受的,所以我们考虑优化。
我们不如把所有询问离线,然后考虑交换询问处理的顺序以减少复杂度。
一种方式就是把左、右端点分别作为第一、二关键字,然后做排序。
但这样就会被排序后所有询问的右端点一大一小的数据卡到 $O(qn)$ 的复杂度。
二次优化
这样排序还是不好,还是会被卡掉,于是我们考虑变换比较函数。
直接双关键字比较不好,那我们就分块后进行双关键字比较。
具体地,遇到两个询问,先按左端点所属块编号从小到大排序,如果相同,则按右端点(不是所属块编号,是原本的下标)从小到大排序。
这样的话,复杂度就是 $O(n \sqrt n+q \sqrt n)$ 的复杂度了。
做法复杂度证明
这个复杂度很多人看了都不理解,这里就证明一下。
(如果没有以下证明,很多人都会认为,这个复杂度还是 $O(qn)$ 的,从而失去很多AC题的机会,所以一定要认真理解)
(我也吃过这个亏,所以有了上面那句话)
我们仿照双指针证明方式,分别去看左、右端点的总变化次数。
右端点
先看右端点移动次数,因为比较好证明。
首先我们看左端点在同一个块内,右端点最多变化几次,显然最多 $O(n)$ 次,一共 $O(\sqrt n)$ 个块,所以这部分总复杂度 $O(n \sqrt n)$。
接下来看左端点换到另一个块的时候,最多变化几次。
显然还是 $O(n)$ 次最多,而左端点最多会进行 $O(\sqrt n)$ 次“换块”的过程,所以这部分复杂度也是 $O(n \sqrt n)$。
所以右端点最多 $O(n \sqrt n)$ 次移动。
左端点
再看比较难证明的右端点移动次数。
我们首先看左端点在“换块”的过程中总共会变化几次,显然最多总共变化 $O(n)$ 次。
接下来看左端点在同一个块内,从前到后总共会变化多少次,显然一次变化最多 $O(\sqrt n)$ 次,最坏情况下所有询问左端点都在同一个块中,所以变化次数最多就 $O(q)$ 次。
所以右端点最多 $O(q \sqrt n)$ 次移动。
证毕。
莫队常数优化
莫队可以配合很多东西,但如果配合的算法常数大,我们就要对莫队算法本身做优化了。
据教练实测,这种常数优化能优化一倍常数。
复杂度瓶颈
首先,我们看上面做法的复杂度慢在哪儿了。
回顾上述证明过程,我们分几个部分来看总复杂度:
- 左端点变化总数:
- 同块最多共变化 $O(q \sqrt n)$ 次。
- 换块最多共变化 $O(n)$ 次。
- 右端点变化总数:
- 同块最多共变化 $O(n \sqrt n)$ 次。
- 换块最多共变化 $O(n \sqrt n)$ 次。
可以发现,复杂度常数大就大在右端点的变化次数上,这里有两倍的常数。
同块的变化总次数已经最优了,无法优化;但换块过程的总次数是可以更优的。
右端点变化
我们把右端点变化的过程画出来:

我们标注一下:
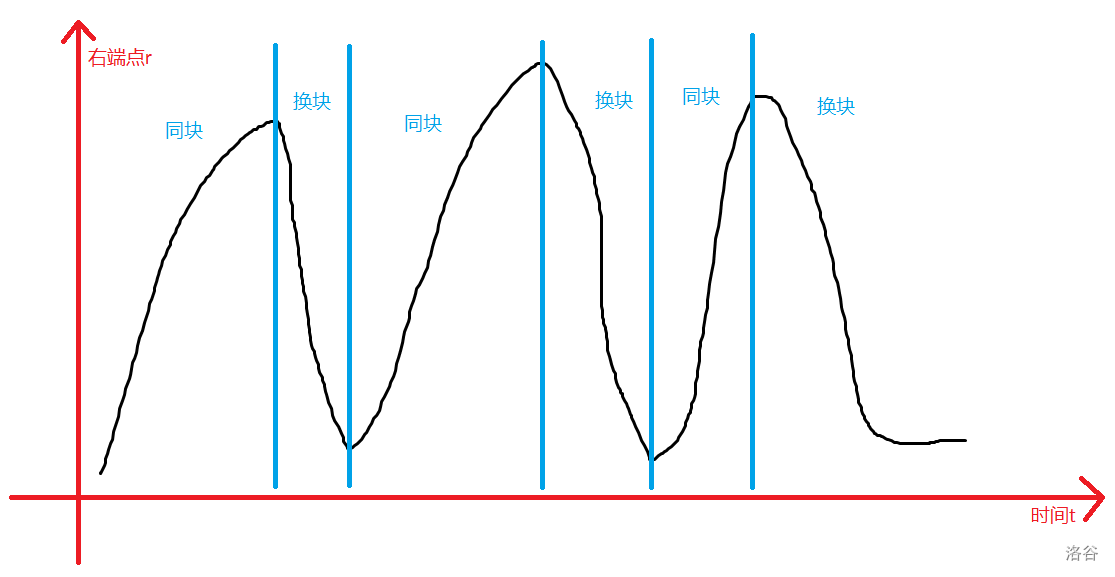
可以发现,每次换块,右端点都要“从头再来”,而降低这个过程所需时间,就可以减少常数。
我们可以考虑按左端点所在块的编号 $x$ 分别考虑,如果左端点所在块的编号不同,还是按编号从小到大排序,否则:
- 如果 $x$ 为奇数,则按右端点从小到大排序。
- 如果 $x$ 为偶数,则按右端点从大到小排序。
这下,这个右端点的变化图就变了:

而这下常数就少了。
高维莫队
此处以三维莫队为例。
三维莫队是说每次修改给你 $(l,r,t)$ 三个参数,让你查询所有满足 $x’ \in [l,r]$ 且 $t’ \leq t$ 的 $(x’,t’)$ 数对的某个权值(此处举个例子)。
这种情况下咋做呢?其实和二维莫队是差不多的。
我们设计一个块大小 $B$,然后先按 $l$ 所在块从小到大排序,然后按 $r$ 所在块从小到大排序,如果都相同,就按 $t$ 从小到大排序。
设块数为 $C$,我们尝试计算一下复杂度。
- 我们先看一下 $t$ 指针移动的总复杂度:
显然对于每个不同的 $(\text{bel}_l,\text{bel}_r)$($\text{bel}_i$ 表示 $i$ 所在块),$t$ 最坏会从最小值移动到最大值($O(n \times C^2)$ 复杂度);然后在换块的时候,再从最大值移动到最小值($O(n \times C^2)$ 复杂度)。
此处设 $l$、$r$、$t$ 的最大值都是 $n$,那么 $t$ 指针的复杂度就是 $O(nC^2)$。
- 我们再看一下 $r$ 指针移动的总复杂度:
在 $\text{bel}_l$ 变化时,$r$ 最坏会从最大值移动到最小值($O(nC)$ 复杂度);而在 $\text{bel}_l$ 不变时,如果 $\text{bel}_r$ 也不变,则 $r$ 每次变化最多 $B$($O(nB)$ 复杂度,注意不是 $O(BC^2)$);但如果 $\text{bel}_r$ 变化,则 $r$ 变化最多 $2B$($O(BC^2)$ 复杂度)。
由于 $O(BC)=O(n)$,所以最后一部分的复杂度就是 $O(BC^2)=O(nC)$;且根据上面复杂度 $O(nC^2)$,我们猜测 $B>C$(因为后面要复杂度均衡);所以 $r$ 指针的复杂度就是 $O(nB)$。
- 最后看一下 $l$ 指针移动的总复杂度:
在 $\text{bel}_l$ 变化时,$l$ 会变化 $2B$ 次($O(BC)$ 复杂度);而在 $\text{bel}_l$ 不变时,$l$ 每次变化最多 $B$ 次($O(nB)$ 复杂度)。
综上所述,$l$ 指针的复杂度就是 $O(nB)$。
然后,我们的目标就是设计 $B$ 和 $C$ 的值,使得这三个部分的复杂度相同。
即 $O(nC^2)=O(nB)=O(nB)$,同时要保证 $BC=n$。
最后一项重复,直接删去,然后把 $n$ 一消,即可得到 $O(C^2)=O(B)$。
由于要保证 $BC=n$,所以 $B=n^{\frac{2}{3}}$,$C=n^{\frac{1}{3}}$。
而复杂度就是 $O(nB)$,即 $O(nC^2)$,带入后得到复杂度为 $O(n \times n^{\frac{2}{3}})=O(n^{\frac{5}{3}})$。
(这个复杂度在 $n=10^5$ 的时候大约为 $2.1 \times 10^8$,在 $n=5 \times 10^4$ 的时候大约为 $6.7 \times 10^7$)
同理,还可以得到四维莫队复杂度为 $O(n^{\frac{7}{4}})$,$k$ 维莫队复杂度为 $O(n^{\frac{2k-1}{k}})$。
(四维莫队复杂度在 $n=10^5$ 的时候大约为 $5.6 \times 10^8$,在 $n=5 \times 10^4$ 的时候大约为 $1.6 \times 10^8$,在 $n=10^4$ 的时候为 $10^7$)
(所以,莫队到四维已经和 $O(n^2)$ 算法差不多了,到五维的时候就根本没必要了,这种情况下就另辟蹊径,或者考虑降维了)
带修莫队
其实所谓的带修莫队,就是三维莫队。
我们给每个输入的修改和查询都附上时刻参数,意思就是在这个时刻进行修改/查询。
然后,在时刻自增时,把这个时刻上的修改操作加入考虑范围;在自减时,就踢出考虑范围。
所以就可以写出代码了,参考M2613。
树上莫队
众所周知,树上莫队只能解决序列问题,但如果搬到树上呢?就需要加一层特殊处理。
在将这种处理方式前,先引入一个知识点。
括号序
括号序也是遍历树得到的序列种类之一。
三大遍历序
实现方式
我目前了解到的有三大遍历序:(下面每个代码里的v都是一个vector,为对应遍历序列)
-
欧拉序(又称“DFS序”)
void dfs(LL x, LL fa){ v += x; erg(i, pre, x){ LL to = a[i].to; if(to == fa) continue; dfs(to, x); } } -
扩展欧拉序(又称“exDFS序”)
void dfs(LL x, LL fa){ v += x; erg(i, pre, x){ LL to = a[i].to; if(to == fa) continue; dfs(to, x); v += x; } } -
括号序
void dfs(LL x, LL fa){ v += x; erg(i, pre, x){ LL to = a[i].to; if(to == fa) continue; dfs(to, x); } v += x; }
性质与应用场景
同时,每个遍历序都有自己的性质和应用场景:
- 欧拉序:
- 对于一个子树,子树内所有节点的欧拉序连续。
- 所以如果把每个节点编号替换成其欧拉序,那么可以直接用树状数组/线段树解决:
- 单点修改节点权值。
- 查询子树内所有节点权值的和/最值/异或和等。
- (待补充)
- 扩展欧拉序:
- 对于一棵树上的任意两个点,这两点在扩展欧拉序上第一次出现的位置组成的区间内深度最小的点就是LCA。
- 所以可以用RMQ更快地解决LCA问题。
- (待补充)
- 括号序:
- 对于树上的链,有一个特殊性质,见下。
- 所以可以解决树上与链相关的问题,不过比较局限,因为上面说的“性质”很复杂。
- (待补充)
括号序的特殊性质
下面说一下括号序的几个特殊性质。
可以发现,每个点在括号序上一定都只出现过刚好 $2$ 次,设点 $x$ 第一次出现在位置 $\text{lef}_x$ 上,第二次出现在位置 $\text{rig}_x$ 上。
然后,我们考虑对于一棵树上的两点 $x$、$y$,考虑在括号序上表示点 $x$ 到 $y$ 的路径上的所有点。
我们分几种情况:
- 如果点 $x$ 和 $y$ 是祖先后代关系(设 $x$ 为 $y$ 的祖先):
- 在括号序的第 $\text{lef}_x \sim \text{lef}_y$ 个位置里,出现过奇数次的所有点,就是点 $x$ 到 $y$ 的路径上的所有点。
- 如果点 $x$ 和 $y$ 没有任何关系:
- 在括号序的第 $\text{rig}_x \sim \text{lef}_y$ 个位置里,出现过奇数次的所有点,加上点 $\text{lca}(x,y)$,就是点 $x$ 到 $y$ 的路径上的所有点。
比如,这棵树:
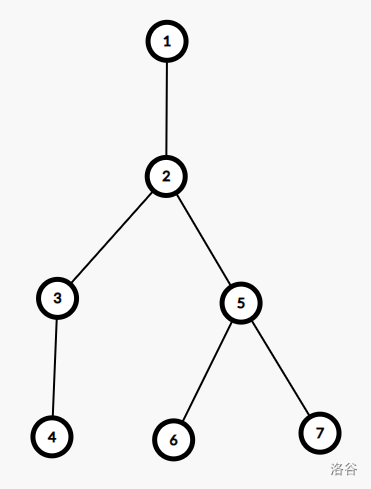
的括号序就是 $[1,2,3,4,4,3,5,6,6,7,7,5,2,1]$。
那么,如果 $x=2,y=6$,则我们看的就是第 $2 \sim 8$ 个位置,出现过奇数次的节点有 $2$、$5$、$6$,正确。
还比如如果 $x=4,y=7$,则我们看的就是第 $5 \sim 10$ 个位置,出现过奇数次的节点有 $3$、$4$、$5$、$7$,加上 $\text{lca}(x,y)=2$,正确。
可以发现,这个性质一定成立。
处理方式
讲完括号序后,我们回到上面说的“处理方式”。
方式简述
根据上面说的性质,你应该就猜到了所谓的方式是啥了。
我们就把括号序求出,然后把询问变成三个参数:
- $l$、$r$:我们看的是括号序的第 $l \sim r$ 个位置。
- $k$:而且不仅要考虑这些位置内出现奇数次的点,还要考虑第 $k$ 个点。
其中,如果 $k=-1$,则不用多考虑。
此时,我们就可以用莫队直接处理了。
代码细节
我们可以用莫队维护 $l$ 和 $r$ 端点,每次添加/删除一个括号序上的下标时,看这个下标上的值(点编号,设为 $x$)出现过的次数的奇偶性来看要加入 $x$ 点的影响还是要剔除 $x$ 点的影响。
此外,在调整完 $l$、$r$ 端点,处理完修改(如果有)之后,我们还要临时加入点 $k$(注意,不是下标 $k$)的影响,然后将答案存入数组,并在存入后,重新删除点 $k$ 的影响。
其他细节见M2621的代码(为树上带修莫队)。
回滚莫队
解决完特殊题型后,我们再回头看普通莫队的变种——回滚莫队。
老规矩,先说题型。
解决题型
在很多题里,你会发现,莫队的add函数很好实现,但del函数却很难实现。
此时,我们就要用到回滚莫队了。
概览
其实回滚莫队的思想很简单,就是通过某种方式让整个莫队里只有add操作。
但这样还是不能实现,我们就再加一个undo操作(撤销操作)。
接下来可以看回滚莫队的算法实现了。
实现
存储修改
在将回滚莫队前,我们要先修改一下原本传统的存储询问结构。
我们要先分块,然后把左端点所在块相同的询问,存到一起。
并且,对于左端点在同一个块的询问,按右端点从小到大排序。
那有人就问了,这样做的用处是啥?接下来你就知道了。
同块处理
接下来,我们来枚举左端点所在块 $i$,并循环所有询问左端点为 $i$ 的询问 $[l,r]$。
那么如果说 $l$ 和 $r$ 在同一个块中,那么直接循环每个 $i \in [l,r]$,并将下标 $i$ 加入影响即可。
全部加入后,直接把答案存储,并重新撤销全部。
异块处理
但如果 $l$ 和 $r$ 不在同一个块中呢?其实也能处理的。
我们设当前考虑的下标区间为 $[nl,nr]$,初始的时候 $nr$ 为块 $i$ 的右端点,并且 $nl=nr+1$,此时考虑范围为空区间。
(如果说不允许空区间,可以干脆把 $nl$ 设为 $nr$,而不是 $nr+1$,同样可以执行下面做法)
然后,由于已经将询问右端点 $r$ 从小到大排序了,所以 $nr$ 必然只会递增,也只会添加元素。
循环到这个询问时,直接暴力调整 $nr$ 即可。
接下来考虑调整 $nl$。
为了方便处理,我们在调整并存入答案后,要把对 $nl$ 的所有修改撤销,让 $nl$ 重新等于初始值。
所以,这里我们就假设 $nl$ 为初始值。
那调整就可以直接调整即可。
总结
可以发现,上面并没有涉及删除下标操作,只有加入下标和撤销操作。
撤销操作可以 $O(1)$ 执行,所以复杂度和普通莫队复杂度相同。
细节
上面说要对于每个左端点所在块都分别存储,那我们就要定义 $\sqrt n$ 个vector,或者 $\sqrt n$ 个长度为 $n$ 的数组。
这样的话,不是常数大,就是空间大。
我们不如直接把每个询问一股脑加入一个数组内,并按左端点所在块排序,如果相同按右端点排序。
然后,在处理时,就可以直接循环,只用判断左端点所在块有没有变化即可。
具体细节见M2622的代码。
莫队二次离线
时隔多年,终于把二次离线搞了。
解决题型
其实顾名思义,二次离线,就是要离线两次。
莫队本身离线了一次。
而如果说,离线一次后,我们无法及时更新add、del(或者undo)操作的影响,也就是无法及时回答query操作。
那么我们就要做一些操作了。
概览
我们考虑再次离线,把这些操作存下来,然后统一处理。
处理之后,把更改或者此时实时的答案存下来。
然后再跑一遍同样的莫队,此时add、del、query全都可以 $O(1)$ 搞出来了。
实现
首先跑一遍莫队,把所有add、del操作记下来。
往往此类操作都会转为前缀和去处理。
然后把这些操作排个序,一遍扫过去就可以搞定了。
记录答案的时候可以维护一个qid,直接存到对应的qid里面。
接下来再次莫队,直接找对应qid的答案,更新即可。
细节
一般情况下,在处理的时候都不是一个一个add或者del的去加操作的。
而是我们对一个区间的操作一股脑加进去。
但这样会有很多细节。
具体可以看P4887代码。